Hacker News is a popular social news website, mostly covering technology and startup topics. It relies on user submissions and moderation, where each submitted story can be upvoted and commented by users, which in term determines whether the story reaches the front page and how long it stays there.
One question that has intrigued me is whether among the topics that are regularly on the front page, are there any that are consistently preferred over others in terms of upvotes or comments? For example, do science news get more or less upvotes than stories on gaming on average? Do bitcoin stories get more or less comments than posts on web design?
Obviously, the variance in such user feedback is huge, so any topic will have both very big and largely ignored stories. But given that tens of thousands of stories make the front page every year, we should be able to see the aggregate differences in topic popularity, if these differences exists.
Luckily, there are tools and libraries available that make answering such questions not only possible, but fairly straightforward.
Libraries used
- Requests – an excellent Python HTTP library for downloading post contents
- Boilerpipe – a library for extracting an article from a webpage and removing all the boilerplate
- BeautifulSoup – HTML parsing, for when boilerpipe fails
- Gensim – robust topic modelling
- Seaborn – Matplotlib extension for beautiful plots
Data
Hckr news provides a convenient archive for accessing all posts that have made it to the front page of Hacker News, together with the number of comments and upvotes for each submission. The total number of posts for 2014 was 35981. Around 34500 of them were still accessible as of January 2015, the rest were returning 4xx or 5xx.
Note that this is different from the set of all Hacker News submissions, since the majority of submissions never make it to the front page.
The following plots show the distribution of upvotes and comments in Hacker News front page stories in 2014 on log scale (for comments, what is shown is log(comments + 1) to accommodate zero comment posts)
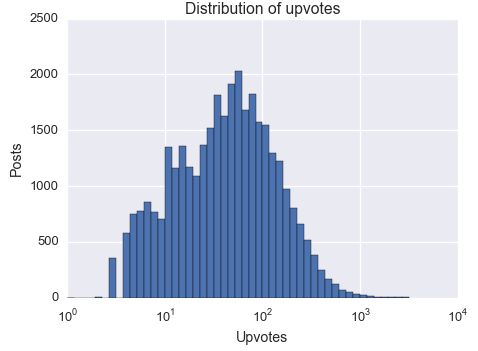

The following scatter-plot shows that while there is a strong correlation between upvotes and comments, there are also quite a few outliers: posts with no comments but a very significant number of upvotes and posts with high comment count but very few upvotes.

Extracting the content
Most webpages include (a lot) of boilerplate text that is usually irrelevant to the actual story that is being linked: “popular posts”, “latest headlines”, terms of service, “follow us” links, etc. All of these pollute the content by introducing a lot of keywords that are not actually related to the article. Fortunately, there are libraries available for removing such boilerplate and extracting the actual article from the page. Boilerpipe is an excellent Java library for doing just that (and it also has python bindings).
Removing the boilerplate and extracting the the textual content is as easy as running
from boilerpipe.extract import Extractor extractor = Extractor(extractor='ArticleExtractor', html=html) extracted_text = extractor.getText()
As usual with such heuristics, it doesn’t work on all pages. In case boilerpipe returns an empty string, I simply extract the textual content of the page (minus content from style and script tags) using BeautifulSoup.
soup = BeautifulSoup.BeautifulSoup(html)
#Strip out style and script content
strip_tags = ["script", "style"]
for tag in soup(strip_tags):
tag.extract()
text = soup.getText(separator = " ")
Learning the topics
There are a number of different methods for extracting topics from a text corpus, from simple tf-idf based heuristics to Latent semantic analysis to sophisticated generative model based approaches. The most popular among the latter is latent Dirichlet allocation.
Latent Dirichlet allocation
LDA is a generative model whereby every document is assumed to come from a mixture of a topics, and every topic is viewed as a multinomial distribution of words. Learning these topics is then a an exercise in Bayesian inference. (Here’s a detailed technical overview paper on LDA and the necessary background on model-based machine learning.)
There are a number of libraries that implement LDA, including Vowpal Wabbit, plda, Mallet etc. The one I’ve found to strike the best balance between ease-of-use and efficiency is Gensim. It implements an online version of LDA, which converges to a good solution relatively fast. It also comes with methods for text cleaning and parsing (including stemming).
Choosing the number of topics.
LDA assumes that the number of topics is given a priori (similar to many clustering algorithms). There are approaches available which learn the number of topics from the data, such as hierarchical Dirichlet process. In practice however, the inferred topic counts and resulting topics are often not what’s expected. The optimal number of topics from the structural/syntactic point of view isn’t necessarily optimal from the semantic point of view. Thus in practice, running LDA with a number of different topic counts, evaluating the learned topics, and deciding whether the number topics should be increased or decreased usually gives better results.
For this dataset, 30 topics (and running 3 passes over the dataset) seemed to strike a good balance of covering a wide enough array of domains, while keeping “junk” and overlapping topics at minimum.
lda = LdaModel(corpus, num_topics = 30, id2word=corpus.dictionary, passes = 3)
Naming the topics
The LDA topics are distributions over words, which naturally lends itself as a naming scheme: just take a number (for example 5-10) of most probable words in the distribution as the topic descriptor. This typically works quite well. There are interesting approaches on how to improve topic naming, for example taking into account word centrality in the word network in the corpus etc. For this particular dataset, the naive top words approach turned out to be descriptive enough.
When looking at the Hacker news dataset, the topics LDA is able to extract from the submitted stories closely tracks the expected, intuitive topics distribution. There are multiple topics on programming, computer systems, startups, but also science, health, government, gaming etc., i.e. topics that are often featured.
Here’s the full list, each named by the top 8 words in the distribution, roughly grouped by their domain . (The latter is done manually and admittedly somewhat arbitrarily.)
| Topic | Domain |
|---|---|
| function-value-code-string-return-list-int-byte | Programming, code |
| memory-thread-performance-code-write-process-data-run | |
| number-point-algorithm-value-example-result-set-problem | |
| return-value-class-self-def-object-method-string | |
| code-javascript-api-html-function-web-application-user | |
| language-type-program-code-programmer-java-write-class | |
| network-device-power-design-technology-system-internet-machine | Computer systems, servers, data and databases |
| data-database-map-table-analysis-information-graph-model | |
| server-client-http-request-service-ruby-connection-user | |
| nameserver-file-net-kernel-dn-com-type-process | |
| file-run-command-install-build-package-docker-version | |
| science-research-human-paper-scientist-university-theory-researcher | Science, space |
| space-nasa-tesla-rocket-launch-star-china-nuclear | |
| project-bug-source-fix-code-open-support-software | Software development, open source |
| company-business-product-market-year-startup-team-million | Startups, business |
| text-color-gallery-line-image-display-file-font | (Web) design |
| currency-btc-usd-fiat-bitcoin-money-price-bank | Money, bitcoin, investing |
| women-health-drug-study-brain-children-patient-cell | Health |
| water-air-land-light-plant-film-earth-sea | Environment |
| security-key-attack-password-hacker-encryption-network-secure | Security, cryptography |
| game-play-design-player-video-work-create-look | Gaming |
| app-apple-phone-device-mobile-android-user-ios | Mobile,apps |
| government-law-state-court-case-public-report-information | Government, law |
| user-link-email-site-service-customer-post-account | Online, computer usage |
| search-page-facebook-web-google-site-music-yahoo | |
| google-microsoft-windows-video-browser-user-support-chrome | |
| year-world-city-american-york-live-state-told | Location, travel, geography |
| work-think-know-way-good-year-look-lot | General |
| com-http-www-emacs-lisp-org-book-pdf | No clear theme ("junk" topics) |
| php-frac-julia-theta-xwl-fff-drosophila-aubyn |
Here are a few examples of top pages within some of the topics, i.e. pages where the proportion of the particular topic is the highest.
Company-business-product-market-year-startup-team-million:
- Airbnb valued at $13B ahead of staff stock sale
- SendGrid Replaces CEO
- Slack raises $120M on $1.12B valuation
Function-value-code-string-return-list-int-byte:
Security-key-attack-password-hacker-encryption-network-secure:
- How PGP Works Under the Hood
- MiniLock – File encryption software that does more with less
- Anonyfish – Chat Anonymously With Another Secret User
Science-research-human-paper-scientist-university-theory-researcher:
- Biefeld–Brown effect
- Solving a mystery of thermoelectrics
- ‘Solid’ light could compute previously unsolvable problems
Game-play-design-player-video-work-create-look:
- FPV with Oculus Rift and a Quadcopter
- 2048 game to the Atari 2600 VCS
- Unofficial Demake Port Of Super Smash Bros Arrives On TI-83/84 Calculators
Google-microsoft-windows-video-browser-user-support-chrome:
- 64-Bit Chrome for Windows
- Mobile Internet Explorer’s New User Agent
- Microsoft announces the Surface Pro 3
Year-world-city-american-york-live-state-told
- The Return of Africa’s Strongmen
- Homeless with GoPro Cameras in SF
- Watch a Street Collapse Swallow an Entire Block of Cars in Baltimore
Women-health-drug-study-brain-children-patient-cell
- Why Seven Hours of Sleep Might Be Better Than Eight
- Long-Term Culture of Stem Cells from Adult Human Liver
- Aspirin could dramatically cut cancer risk, according to biggest study yet
The top posts for each topic seem to match the topic descriptors quite well, which is a nice high level sanity check that they indeed capture the expected content of the stories.
When looking at the distributions of the topics, i.e. the average proportion of a topic in a page, we see that the general topics are at the top, while the junk, hard-to-interpret topics are at the bottom, showing that they are indeed outliers. The proportion of programming or computer system related topics are not at the top individually, but this is due to the fact that they are divided into several subtopics. On aggregate, programming and computer related topics clearly dominate.

We are finally ready to look at the upvote and comment distribution per topic. For this, we divide the upvotes and comments of each page proportionally between the topics assigned to that page. We then normalize the scores for each topic by the proportion of that topic in the whole corpus, so that each topic’s scores lies on the same scale. The following plot shows the average upvotes per topic, together with 95% confidence interval bars to make sure that the differences are statistically significant (the green line denotes the mean number of upvotes over all front page posts):

The most upvoted topics are software and open source project related, topics on government and law (prominent examples of the latter being posts on Snowden, EFF etc) and mainstream tech news (such as major announcements from Google and Microsoft) and game related stories.
At the bottom of the scale are science, health, environment, geography related news. These are topics that aren’t the “core” topics for Hacker news (which is technology and startups) and they are in general also non-controversial, when compared to topics related to government/law, money/bitcoin etc. This is well illustrated by the plot of the average number of comments per topic:

In the top we again see mainstream tech related posts, but also money and bitcoin related news, law/government, mobile/apps stories. The topics with the least amount of comments seem to be the most technical ones: science, algorithms, data/databases, code, optimizations etc.
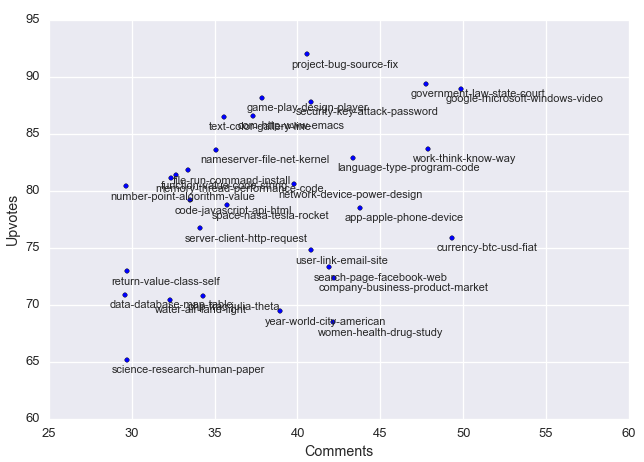
When looking at the scatter plot of upvotes vs comments, we see that while there is a correlation between the two, the ratio can vary quite significantly. There are a few things that stand out. Bitcoin/money related news, while not that highly upvoted get a lot of discussion; the (open source) software topic gets the most upvotes despite being only mediocre in the amount of discussion it generates; the programming topics cluster, which are mostly similar in being low volume in terms of discussion, but still getting solid upvoting from the community. And finally, science is clearly the least favorite front page topic on Hacker News.
Conclusions
We can see that there are clear differences between topics in terms of upvoting and commenting. In general, the results seem to match the intuitive expectations of Hacker News content quite well. First of all, the extracted topics and their descriptions are clearly in line with the intent of the page. Secondly, we see that topics that are more controversial or polarizing indeed create the most amount of discussion and to an extent it also translates to upvotes. At he same time, the more technical topics receive a lot fewer comments on average.
There are a number of interesting things still to look at:
- The evolution of topics over time – which topics have increased and which ones decreased in popularity over time?
- Analyzing all submissions. In this analysis, we only looked at posts that actually made it to the front page. Another interesting study would be to look at all posts that are submitted. This is however non-trivial, since important stories usually have multiple posts from different sites covering the same story. Generally only one of them gets picked up to to be on the front page. For the analysis, these close duplicates would have to be filtered out.
- The structure of posts – is there anything in the post structure, word usage or similar that makes it hit big on the front page?
How do you feel about releasing the dataset?
Thank you for a great post! It’s well balanced between theory, technicalities and results. I was going to comment on the need to analyze all submissions to have some insight on the topics shared on Hacker News that do not make it onto the front page, but I noticed that you already pointed that out in your conclusion.
As teapot01 already stated, will you be sharing the dataset at any point in time?
Pingback: Which topics get the upvote on Hacker News? | Premium Blog! | Development code, Android, Ios anh Tranning IT