An aspect that is important but often overlooked in applied machine learning is intervals for predictions, be it confidence or prediction intervals. For classification tasks, beginning practitioners quite often conflate probability with confidence: probability of 0.5 is taken to mean that we are uncertain about the prediction, while a prediction of 1.0 means we are absolutely certain in the outcome. But there are two concepts being mixed up here. A prediction of 0.5 could mean that we have learned very little about a given instance, due to observing no or only a few data points about it. Or it could be that we have a lot of data, and the response is fundamentally uncertain, like flipping a coin.
For regression, a prediction returning a single value (typically meant to minimize the squared error) likewise does not relay any information about the underlying distribution of the data or the range of response values we might later see in the test data.
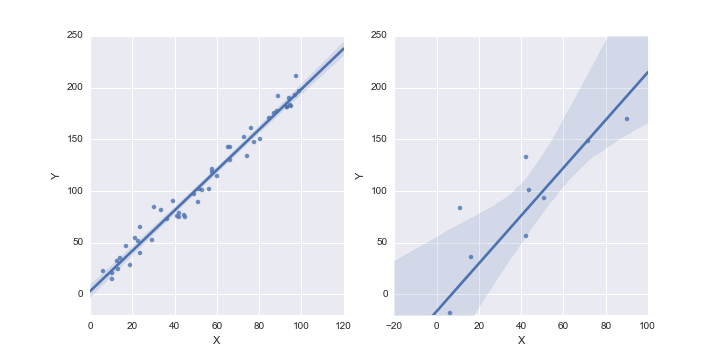
Looking at the following plots, both the left and right plot represent similar, learned models for predicting Y from X. But while the model predictions would be similar, confidence in them would be quite different for obvious reasons: we have much less and more spread out data in the second case.
A useful concept for quantifying the latter issue is prediction intervals. A prediction interval is an estimate of an interval into which the future observations will fall with a given probability. In other words, it can quantify our confidence or certainty in the prediction. Unlike confidence intervals from classical statistics, which are about a parameter of population (such as the mean), prediction intervals are about individual predictions.
For linear regression, calculating the predictions intervals is straightforward (under certain assumptions like the normal distribution of the residuals) and included in most libraries, such as R’s predict method for linear models.
But how to calculate the intervals for tree based methods such as random forests?
Quantile regression forests
A general method for finding confidence intervals for decision tree based methods is Quantile Regression Forests.
The idea behind quantile regression forests is simple: instead of recording the mean value of response variables in each tree leaf in the forest, record all observed responses in the leaf. The prediction can then return not just the mean of the response variables, but the full conditional distribution \(P(Y \leq y \mid X = x)\) of response values for every \(x\). Using the distribution, it is trivial to create prediction intervals for new instances simply by using the appropriate percentiles of the distribution. For example, the 95% prediction intervals would be the range between 2.5 and 97.5 percentiles of the distribution of the response variables in the leaves. And of course one could calculate other estimates on the distribution, such as median, standard deviation etc. Unfortunately, quantile regression forests do not enjoy too wild of a popularity. While it is available in R’s quantreg packages, most machine learning packages do not seem to include the method.
Random forests as quantile regression forests
But here’s a nice thing: one can use a random forest as quantile regression forest simply by expanding the tree fully so that each leaf has exactly one value. (And expanding the trees fully is in fact what Breiman suggested in his original random forest paper.) Then a prediction trivially returns individual response variables from which the distribution can be built if the forest is large enough. One caveat is that expanding the tree fully can overfit: if that does happen, the intervals will be useless, just as the predictions. The nice thing is that just like accuracy and precision, the intervals can be cross-validated.
Example
Let’s look at the well-known Boston housing dataset and try to create prediction intervals using vanilla random forest from scikit-learn:
from sklearn.ensemble import RandomForestRegressor import numpy as np from sklearn.datasets import load_boston boston = load_boston() X = boston["data"] Y = boston["target"] size = len(boston["data"])
We’ll use 400 samples for training, leaving 106 samples for test. The size of the forest should be relatively large, so let’s use 1000 trees.
trainsize = 400 idx = range(size) #shuffle the data np.random.shuffle(idx) rf = RandomForestRegressor(n_estimators=1000, min_samples_leaf=1) rf.fit(X[idx[:trainsize]], Y[idx[:trainsize]])
We can now define a function to calculate prediction intervals for every prediction:
def pred_ints(model, X, percentile=95):
err_down = []
err_up = []
for x in range(len(X)):
preds = []
for pred in model.estimators_:
preds.append(pred.predict(X[x])[0])
err_down.append(np.percentile(preds, (100 - percentile) / 2. ))
err_up.append(np.percentile(preds, 100 - (100 - percentile) / 2.))
return err_down, err_up
Let’s compute 90% prediction intervals and test how many observations in the test set fall into the interval.
err_down, err_up = pred_ints(rf, X[idx[trainsize:]], percentile=90)
truth = Y[idx[trainsize:]]
correct = 0.
for i, val in enumerate(truth):
if err_down[i] <= val <= err_up[i]:
correct += 1
print correct/len(truth)
0.905660377358
This is pretty close to what we expected: 90.6% of observations fell into the prediction intervals. Plotting the true values and predictions together with error bars visualizes this nicely.

If we set prediction interval to be 50% for the same model and test data, we see 51% of predictions fall into the interval, again very close to the expected value . Plotting the error bars again, we see that they are significantly smaller:

What can also be observed on the plot that on average, predictions that are more accurate have smaller prediction intervals since these are usually “easier” predictions to make. The correlation between absolute prediction error and prediction interval size is ~0.6 for this dataset.
And again, just as one can and should use cross-validation for estimating the accuracy of the model, one should also cross-validate the intervals to make sure that they give unbiased results on the particular dataset at hand. And just like one can do probability calibration, interval calbiration can also be done.
Caveats
There are situations when the tree is not expanded fully, such that there is more than one data point per leaf. This can happen because either
a) a node is already pure, so splitting further makes no sense, or
b) the node is not pure, but the feature vector is exactly the same for all responses, so there isn’t anything to do a further split on.
In case of a), we know the response and node size, so we still know the distribution perfectly and can use it for calculating the intervals. If case b) happens, we are in trouble, since we don’t know the distribution of responses in the non-expanded leaf. Luckily, the latter very rarely happens with real world datasets and is easy to check for.
Conclusions
Utilizing prediction intervals can be very beneficial in many machine learning and data science tasks, since they can tell a lot about the underlying data that we are learning about and provide a simple way to sanity check our results. While they seem to enjoy relatively widespread use for linear models due to the ease of access with these methods, they tend to be underutilized for tree-based methods such as random forests. But actually they are relatively straightforward to use (keeping the caveats in mind) by utilizing the fact that a random forest can return a conditional distribution instead of just the conditional mean. In fact, estimating the intervals this way can be more robust than prediction intervals for linear methods, since it does not rely on the assumption of normally distributed residuals.
I have tried this implementation (pred_ints(rf, X[idx[trainsize:]], percentile=90)) for more than 10 times, but the results (i.e., correct/len(truth)) were all below 0.90 (ranging from 0.60 to 0.85)……
Turns out copy-pasting the code into the blog messed up the indentation in the pred_ints function (causing calculating the percentiles within the loop instead of once the loop over trees is done). Should be fixed now and the results better:)
Actually that’s not right. Here is the correct way: http://arxiv.org/abs/1404.6473
Not sure what you mean by “not right”. What i’m describing is literally fully expanded quantile regression forest (http://www.jmlr.org/papers/volume7/meinshausen06a/meinshausen06a.pdf) .
Also, the paper you point to is about calculating confidence intervals, which is a distinct concept from prediction intervals, which is the topic of this post.
I don’t think it is right either. In the paper you quoted, it is using the distribution of all training set samples that share the same leaves as the point to be predicted as an approximation.
In your example, you are using the distribution of the means of each tree, which has way smaller variance.
No. You don’t use the means, since you’re expanding the trees fully. The distribution you get out is not of means, but of the original individual response values.
I see what you are saying. If each leaf contains only one data point, then the mean of sample points under a leaf is the same as the value of the sample point…
The thing is that min_samples_leaf=1 only guarantees that there is at least one data point per leaf. How do you know the tree is fully expanded?
There is always at least one data point per leaf, with or without this parameter ( you cant have a leaf with 0 data points). What it means is that the tree should be expanded until only one value is in the leaf. You are right that there could be a situation where the split isn’t done further. This can happen because
a) the node is already pure, so splitting further makes no sense.
b) the node is not pure, but the feature vector is exactly the same for all responses, so there isn’t anything to do a further split on.
For a), we know the response and node size, so we still know the distribution perfectly.
For b) we are indeed in trouble. I haven’t come accross a real world regression dataset where this happens, but in theory it definitely could. Luckily, it is trivial to check via inspecting the trees.
I should add this caveat to the post, thanks for bringing it up.
Pingback: Distilled News | Data Analytics & R
Could you explain what the true values are in your plot? My boston-data is much more messy. Very good article, thx.
The true values are simply sorted by their actual values (and the associated predicted values are carried with them). This makes the plot nice and monotonous/smooth, otherwise the values would indeed be all over the place.
Care to share how?
Great article,
scikit-learn has a nice method for prediction intervals using gradient boosting ensembles, but not for RF!
Bummer! I will steal your code snippets for the RF case.
Thank you again
Nice post!
I was using similar techniques for a project recently and indeed ended up using Gradient Boosting in scikit-learn because it provides quantile regression.
With your method, what would you reckon if the cross-validation shows that you overfit your confidence interval? As you expand your tree fully, you can’t tune the parameters related to the number of samples in each leaf to control the overfitting. Is there any other parameter you can think of to control overfitting (apart maybe from increasing the number of trees?)
Thanks
I guess the number of trees and max_features are the only two options to avoid overfitting. What could also work is actually fitting the tree without fully expanding it, and then calibrating/adjusting the intervals via crossvalidation like with probability calbiration.
Look at the GridSearchCV and RandomSearchCV classes in scikit-learn. You can provide a dictionary of search lists for each of the hyper parameters for RandomForestClassifier.
I tried to use the RFECV class. I killed it eventually (it can take a long time) because the Stackoverflow posts that mentioned it weren’t very enthusiastic. However, I like the idea for feature selection. Note you need to inherit from RandomForestClassifier in version 0.16 (to be fixed in 0.17). http://stackoverflow.com/questions/24123498/recursive-feature-elimination-on-random-forest-using-scikit-learn
Not sure how search over hyperparamers helps here (which is what you suggest if i understand correctly). This does not help the fact that expanding the tree fully can overfit your data, but if you prune the trees, you lose the ability to calculate quantiles on the leaves of vanilla scikit RF trees.
With that said, you can actually do this in current scikit-learn master, by keeping track of all training data labels. I’ll follow up with blog post.
Pingback: DataAspirant August2015 newsletter | dataaspirant
I am not able to get the last chunk of code to work, it just freezes my computer. Also, where is the code for the graphs because that is what I am most interested in?
Thanks
Just to confirm. For regression problems, assuming that it is rare that feature vectors would be exactly the same, caveats b does not exist. For caveat a, how to check node size as the model just return a response value? Thanks!
Thanks for the post, the function pred_ints was helpful for my problem.
Thanks buddy.. Very helpful. Wonder why something of this sort isn’t readily available in base scikit-learn package.
Hi, thanks for a great article.
I’m trying to run the code and replicate the results but they are totally off. Had something changed in scikit-learn that make this code generate errors?
I use Python 3.6.0 and scikit-learn 0.18.1
The full code I run to replicate the plot is:
— BOF rf_boston.py —
from sklearn.ensemble import RandomForestRegressor
import numpy as np
from sklearn.datasets import load_boston
import pandas as pd
boston = load_boston()
X = boston[“data”]
Y = boston[“target”]
size = len(boston[“data”])
trainsize = 400
idx = list(range(size))
#shuffle the data
np.random.shuffle(idx)
rf = RandomForestRegressor(n_estimators=1000, min_samples_leaf=1)
rf.fit(X[idx[:trainsize]], Y[idx[:trainsize]])
def pred_ints(model, X, percentile=95):
err_down = []
err_up = []
err_mean = []
for x in range(len(X)):
preds = []
for pred in model.estimators_:
preds.append(pred.predict(X[x].reshape(1,-1))[0])
err_down.append(np.percentile(preds, (100 – percentile) / 2. ))
err_up.append(np.percentile(preds, 100 – (100 – percentile) / 2.))
err_mean.append(np.mean(preds))
return err_down, err_up,err_mean
err_down, err_up,err_mean = pred_ints(rf, X[idx[trainsize:]], percentile=95)
truth = Y[idx[trainsize:]]
correct = 0.
for i, val in enumerate(truth):
if err_down[i] <= val <= err_up[i]:
correct += 1
share_correct = correct/len(truth)
print(share_correct)
#% Store in DF
df = pd.DataFrame()
df['v']=truth
df['p_d']=err_down
df['p_u']=err_up
df['p']=err_mean
#Plot DF
a=df.sort_values(['v']).reset_index()
plt.scatter(a.index,a.v,color='green')
plt.errorbar(a.index,a.p,yerr=[a.p_d,a.p_u])
—– EOF —-
And an example of the plot I get can be seen here: https://dl.dropboxusercontent.com/u/20904939/rf_boston.png
Note that the prediction intervals are WAY bigger than in this original blog post. I've been scratching my head for a while about this, and any help would be appreciated!
Probably a bit late, but: Carina, your error bars should be plotted with:
plt.errorbar(a.index,a.p,yerr=[a.p -a.p_d, a.p_u – a.p])
I too would appreciate it if you would post the code that produced your plots.
Pingback: Prediction intervals for Random Forests | Premium Blog! | Development code, Android, Ios anh Tranning IT
Pingback: Les intervalles de prédiction | OCTO Talks !
I really liked your article, though I noticed that the pred_ints function runs slowly for a larger number of samples. I modified your code to do batch predictions instead of iterating over each sample:
def pred_ints(model, X, percentile=95):
err_down = []
err_up = []
preds = []
for pred in model.estimators_:
preds.append(pred.predict(X))
preds = np.vstack(preds).T
err_down = np.percentile(preds, (100 – percentile) / 2., axis=1, keepdims=True)
err_up = np.percentile(preds, 100 – (100 – percentile) / 2., axis=1, keepdims=True)
return err_down.reshape(-1,), err_up.reshape(-1,)
Hi,
Nice article! I just have a suggestion on pred_ints function, you’ll have a great performance gain using vectorial functions:
def prediction_intervals(model, X, percentile=95):
predictions = np.array([pred.predict(X) for pred in model.estimators_])
err_down = np.apply_along_axis(lambda x: np.percentile(x, (100 – percentile) / 2.), 0, predictions)
err_up = np.apply_along_axis(lambda x: np.percentile(x, 100 – (100 – percentile) / 2.), 0, predictions)
return np.transpose(np.array([err_down, err_up]))
Would this approach also work for a gradient boosted decision tree? i.e. both RF and GBDT build an esemble F(X) = \lambda \sum f(X) so pred_ints(model, X, percentile=95) should work in either case. Whilst most GBDT libraries have a quantile loss function it’s inconvient to fit both mean and quantile models.
On the other hand, using say CatBoost I don’t see how you can ensure there’s only 1 sample per leaf – catboost uses oblivious decision trees which applies the same split for every node at the current level.
err_down.append(np.percentile(preds, (100 – percentile) / 2. ))
What is the meaning behind the division with two?
If you are looking for 95% confidence interval , you want cutoffs at 2.5 from one end and 2.5% the other end
Hi will this work with an already tuned RF model?
Just wondering
Very nice explanation. This article saved me a lot of time. Thank you very much!
Hi. Thanks for this interesting and useful post. I am currently applying this method with the help of this post and some other sources, including Meinchausen’s paper. I just want to confirm if I understood one thing correctly: it doesn’t matter if a cross validation of the hyperparameters is done; when training the algorithm with the final training data set, the model always predicts the exact training values because the min_samples_leaf hyperparameter is set to 1, am I right? However, since the hyperparameters were adjusted by cross validation, the generalization error has already been minimized. am I interpreting this correctly?
Thanks in advance.
I am not sure about this statement:
b) the node is not pure, but the feature vector is exactly the same for all responses – very rarely happens with real world datasets.
Are you implying this:
Same input features (X) can result in a wide variety of outputs (Y).
If yes, then I would argue that this does happen in a lot of practical use-cases. [You wont always have access to all the possible features to model some scenario / activity – so using a subset of features would result in this]
If this situation happens, it should still be possible to generate the prediction intervals I think. Take out the entire vector of responses from the leaf and combine with other vectors from next trees. Do the quantile logic on the concat of all these vectors..